I started my journey with the Personal Data Pipeline project early last year and you can see in that post my initial motivations and how far I got with the concept. What I wanted out of getting this live was to get a sense of whether or not this idea would actually work and if it resonated with "the world" at large. I didn't get a 6-figure Patreon sponsorship or anything but I connected with a few like-minded folks, learned about some interesting pieces of technology out there, and got the attention of a company that offered me a job. All-in-all, I would call that a success!

Now, almost a year after that post went live, I'm thinking about this project again and what comes next. I'm still a big believer in being mindful about generating data in for other companies, I still want a local copy of as much of that data as I can, and I still want to figure out how to get the most of out that data combined with the all the notes that I take. The values I outlined in that post are the same and feel just as important as before:
- Files instead of apps, local first (own your data)
- Open source, work in public (transparency)
- Personal data privacy ahead of everything else
It feels good that the reasons I originally started working on this are the same as before but those good intensions can't actually materialize something that works or exists. So I've been thinking more about what I would actually want out of a system like this. In no particular order:
- I want to be able to query my cloud data locally, including being able to join between sources.
- I want to be able to push this data into my notes application, Obsidian, in a reliable way.
- I want to push data from my notes application into other applications so I can access it in certain contexts.
- I want to be able to download everything I can from a cloud source and then delete that whole source if I'm not using it anymore or delete records at a certain age.
- I want to be able to run a local LLM/AI agent with all of this data in context to more easily find information and, potentially, find connections that I wouldn't have found otherwise.
It sort expands to infinity from there but it all centers around gathering, organizing, storing, and managing all of my data right here on the laptop where I'm writing this post in a local Markdown file. The common first step for of all these things is "get the data and store it in a useful format."
So, to that end, I'm going to focus on working with DuckDB under the hood to pull in the raw JSON and store it in a tabular format that's easy to work with and reason about. All that logic is currently represented in a recipe, like this one. But that method overloads the output step quite a bit and would require duplication across recipes when source data needs cleanup or when tables are joined. It also leaves out an opportunity to work with your data using raw queries once it's all stored in a table format.
With this middle step, we have something more like this:
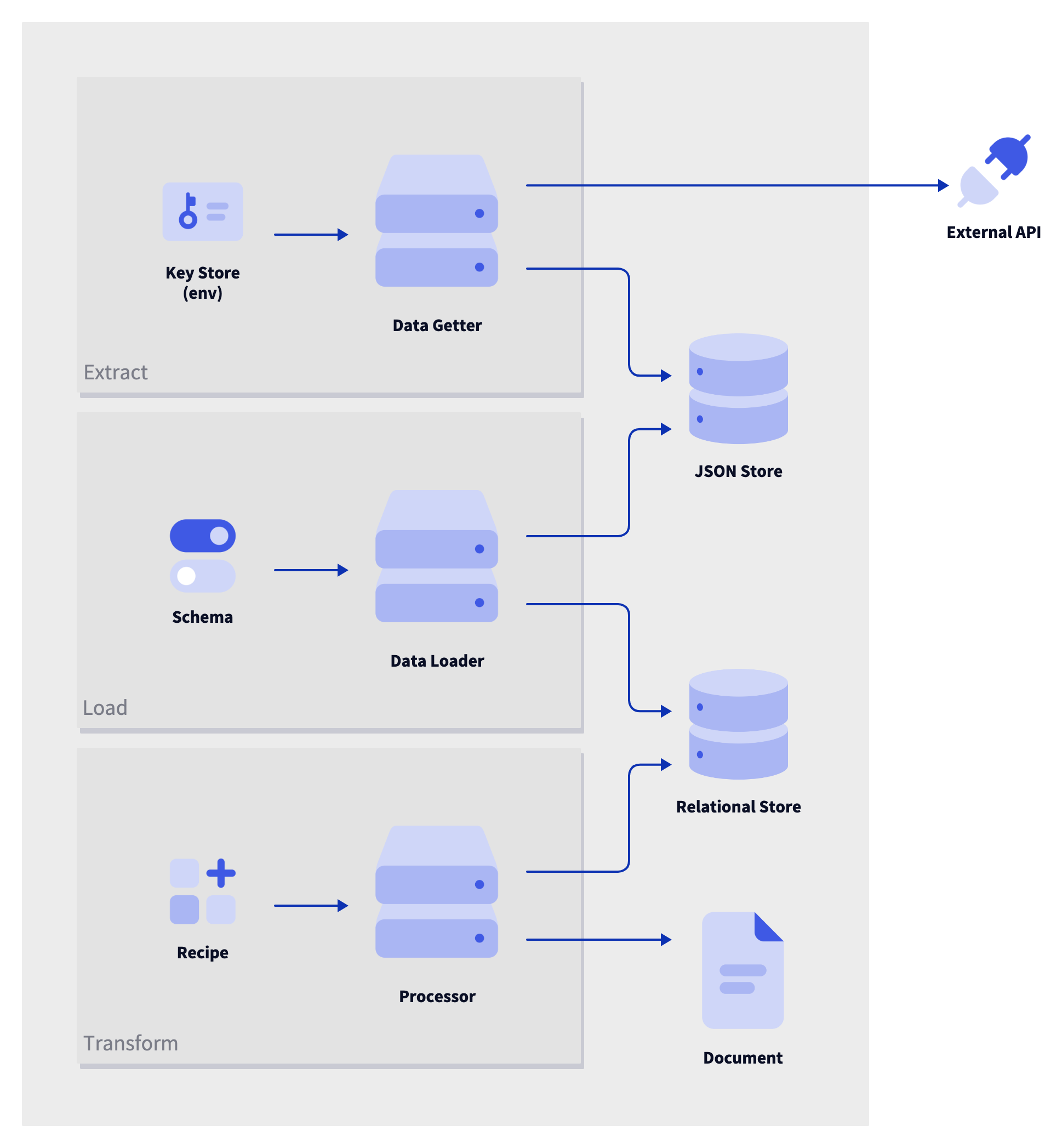
A few notes on the above:
- I imagine the relational store tables being automatically truncated and rebuilt at whatever interval is indicated in configuration. This is just a representation of the raw JSON data at rest so faulty transformations can be rectified with a rebuild from scratch.
- I like the recipe concept for representation here as well. That was initially a big challenge when I was building the first version. It turns out, representing a SQL dialect in YAML is hard! I think this can initially just be plain DuckDB SQL scripts with templates to assist.
- Once the tables are built, we can use the DuckDB local UI to examine the output and start coming up with interesting combinations. In fact, this could be where a lot of people stay now that the data is in one place and ready to explore.
This feels like a good milestone for this project and a place where I can start thinking about what I really want to do with the data that I have.
Beyond that ... I definitely don't have all the answers and if I'm going to solve even a small part of this, I have to keep talking to people that care about this in their own lives and operate with similar values. To that end, I'm going to start working on this project in a more formalized way and writing more about what I'm thinking, what I've found, and where I'm going with this.
- General posts about ideas, architecture, and direction will be posted here and duplicated on the PDPL Substack so they get emailed out.
- New releases will be listed on GitHub with more information posted on Substack (keep an eye out for v0.13.0 soon)
- Development logs will stay on GitHub for now but I'd like to find a better home for them somewhere. I'll link to relevant ones in the release notes.
As always, please reach out if you have any questions, comments, or ideas!
< Take Action >
Comment via:
Subscribe via:
< Read More >
Tags
Newer

May 13, 2025
Thoughts on AI
I felt the need to write out my thoughts about AI, generally, and from the software engineering perspective. As with all my posts, all unquoted words here are my own.
Older

Aug 07, 2024
My Values for Technical Leadership
My professional values as an engineer, architect, and technical leader.